
Spark is the shiny new thing in big data, but how will it stand out? Here’s a look at “fog computing,” cloud computing, and streaming data-analysis scenarios.
by James Kobielus
To survive the competitive struggles, every fresh technological innovation must find clear use-cases in the marketplace. There must be some specific itch that the new approach can scratch at least as well, and hopefully much better, than the alternatives.
As the mania for Apache Spark grows in the big-data analytics arena, we must remember that it’s still an unproven technology. The early crop of commercial solutions that implement Spark haven’t yet converged on distinctive use-cases that call for Spark and no, say, Hadoop, NoSQL, or established low-latency analytics technologies. What is Spark’s application sweet-spot?
When you ponder Spark’s prospects, you must consider a related question. What exactly are the core deployment models and use-cases for which Spark is best suited in today’s crowded big data marketplace? What differentiators does Spark have over rival platforms, whether open source or proprietary, for addressing these requirements? And do these differentiators, taken as a whole, provide sufficient impetus for Spark to find its commercial sweet-spot rapidly and thereby achieve widespread adoption?
With these questions hanging in your mind, here are the principal deployment models in which Spark may prove its value in real-world applications:
Fog
The Internet of Things (IoT) may spell the end of data centers as we’ve traditionally known them. Data centers’ core functions — processing and storage — are increasingly being decentralized out to the network’s edges. The IoT is also greatly expanding the need for distributed, massively parallel processing of huge amounts of machine and sensor data of all sorts. Not just that, but the analytics required in these “fog computing” scenarios will increasingly emphasize low-latency, massively parallel processing of machine learning and graph analytics algorithms of great complexity.
As I detail here, fogs are clouds in which the primary processing nodes are network-edge endpoints, such as sensor-laden Internet of Things (IoT) devices. Fogs distribute the storage, bandwidth and other cloud resources out to the IoT endpoints, most of which are embedded deeply in the hardware infrastructure of the end applications. These fog requirements feel tailor-made for Spark, which includes an interactive real-time query tool (Shark), a machine-learning library (MLib), a streaming-analytics engine (Spark Streaming), and a graph-analysis engine (GraphX). As the IoT industry converges, sometimes haltingly, toward a common fog infrastructure, Spark may just fulfill that niche better than any other open source platform.
Cloud
Spark, building on HDFS, clearly has the ability to shoulder practically any Hadoop cloud deployment model and use-case, not just those associated with the IoT. As a start, Spark can access and process data stored in HDFS, HBase, Cassandra, and any other Hadoop-supported storage system. As a general-purpose cloud platform, Spark boasts performance advantages vis-à-vis Hadoop, most notably Spark’s ability to parallelize models in real-time across distributed in-memory clusters. And unlike Hadoop’s MapReduce, Spark can combine SQL, streaming, and graph analytics within cloud analytics applications. Clearly, the cloud market seems ripe for Spark, especially in an era where distributed, heterogeneous storage layers, streaming low-latency middleware, and in-memory cloud platforms are in the ascendance.
Stream
Spark may ride its adoption in IoT and cloud environments to become ubiquitous for stream-computing applications of all kinds. Some industry observers question whether Spark truly supports all the key requirements for robust stream processing. One might argue that other open source stream-computing platforms, such as Apache Storm and Apache Samza, have better performance, functionality, or development features than Spark for these use-cases. But one might just as well argue that Spark’s advantages as a fog and cloud analytics platform lessen the need for it also to be the slam-dunk choice for stream computing. If Spark can support streaming analytics reasonably well for the majority of use-cases, it might also become the standard there as well.
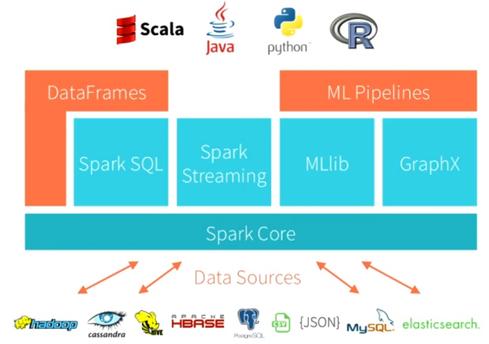
 Apache Spark supports SQL, machine-learning, graph, and streaming analysis against a range of data types, and in multiple development languages.
Apache Spark supports SQL, machine-learning, graph, and streaming analysis against a range of data types, and in multiple development languages.
What might prevent Spark from achieving widespread adoption in any or all of these markets is not just the presence of established platforms and tools (e.g., Hadoop) that adequately address 90% of the core use-cases. Over the next two to three years, the key obstacle to widespread Spark adoption may simply be Spark’s immaturity, the paucity of field-proven, enterprise-grade Spark platforms, and the lack of a well-developed ecosystem of Spark tools, libraries, and applications.
Considering that many enterprises have now committed to Hadoop and various NoSQL platforms as their strategic big-data platforms, they may be reluctant to commit to Spark until it has truly proved its value in a sufficient number of real-world deployments. Likewise, most organizations with stream-computing requirements have already committed themselves to a commercial solution or perhaps an alternative open source platform.
Spark is the latest shiny new big-data bauble. To make the most of its “next-big-thing” status, Spark promoters will need to generate actual user demand for the technology. Advocates should avoid pitching it at customers who’ve become jaded by the incessant drumbeat for all things big data, especially Hadoop.
Spark will naturally float to its proper level in the big data ocean. Hyping it out of proportion to its competitive differentiation would only inspire a backlash. And that would be counterproductive for Spark in the long run, and deter potential users from considering it long before they’ve had their first serious opportunity to kick the tires.
James Kobielus is IBM’s Big Data Evangelist. He is an industry veteran who spearheads IBM’s thought leadership activities in big data, data science, enterprise data warehousing, advanced analytics, Hadoop, business intelligence, data management, and next best action … View Full Bio
Seen at informationweek.com.